AI Coding Tools Evolution and Vibe Coding
8/28/2025
Recently, discussions about AI-assisted programming and Vibe Coding have been very intense. After thinking about it, I decided to write a blog to express my own views.
I started using GitHub Copilot in 2023, began continuously using Cursor in 2024, and started using Claude Code extensively a few months ago.
Although I haven't had time to try all AI IDEs on the market, I think these three products have milestone significance for AI-assisted programming. I can say I've accumulated some experience to talk about Vibe Coding.
Vibe Coding Is Not A Good Name
Vibe Coding (translated as "atmosphere programming" in Chinese) went from being unknown to being discussed by every programmer. It should have started with this tweet from Andrej Karpathy (former Tesla AI Director and one of OpenAI's founding members).
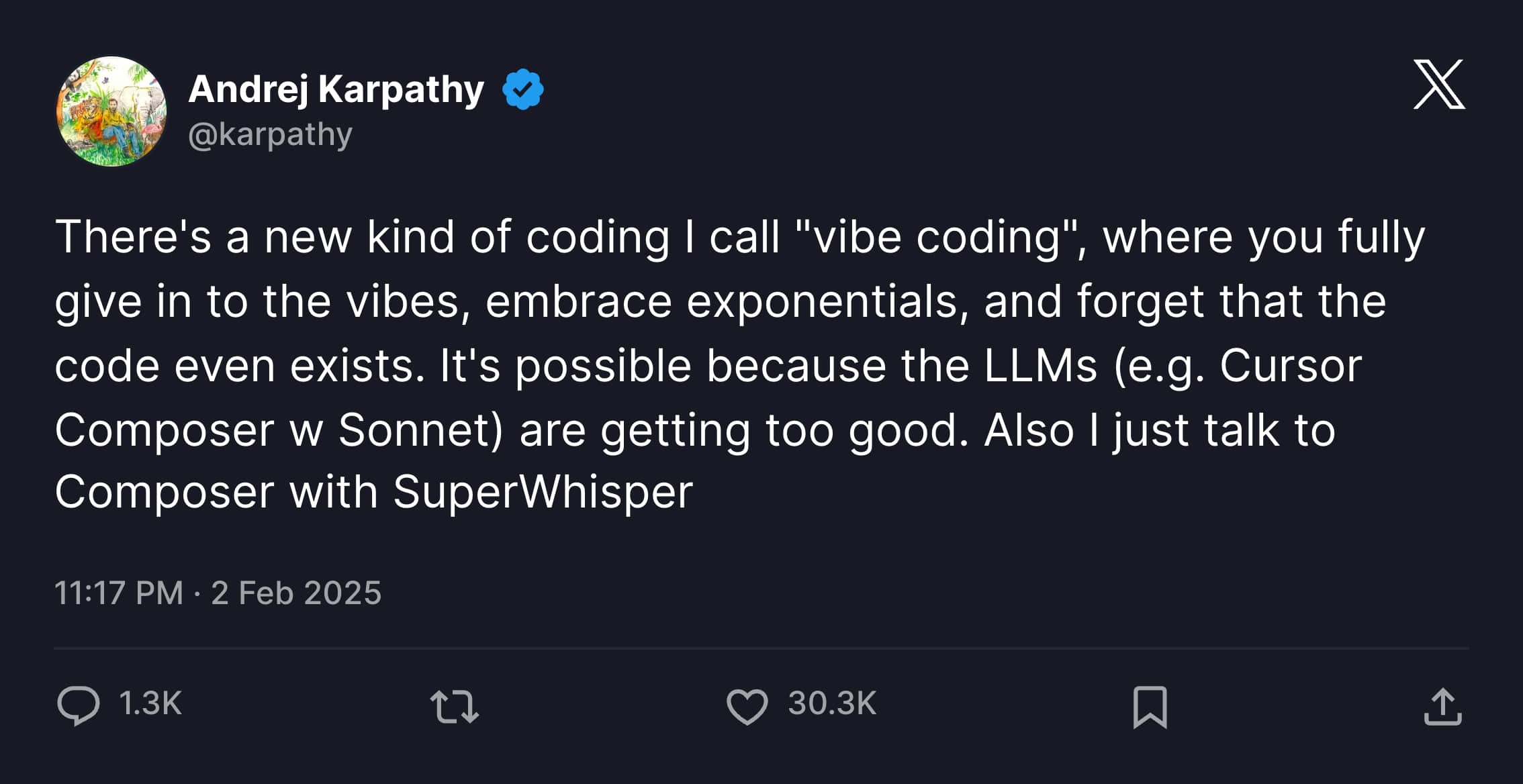
I'll paste the original text below:
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
I generally don't like arguing over words, but since "vibe coding" has become a universal term, with all AI-assisted coding tools and methods now uniformly called "vibe coding", I think it's necessary to make distinctions.
Based on the original text, I think Andrej Karpathy's definition of "vibe coding" has several key points:
- forget the code even exists -> Forget that code exists.
- Barely manually participate in programming; even the smallest errors are fixed through AI rather than manual changes.
- No longer review AI-written code, only look at results. If unsatisfied, continue the conversation.
- For throwaway projects, it's not bad and quite amusing.
So I understand that "vibe coding" originally discussed a new programming method - a way of programming completely based on LLM conversation.
Maybe because "vibe coding" is hard to translate or lacks clear meaning, it has indeed developed into a situation where any programming assisted by AI tools or code written through AI is uniformly called Vibe Coding.
I think the reason for many current discussions and debates is the failure to distinguish between these two approaches.
Maybe one could be called "vibe coding" and the other could be called AI-assisted programming, AI Coding, Agents Coding, or Context Coding.
Although these two programming methods are fundamentally different, I still want to discuss basic AI-assisted programming methods before talking about vibe coding.
Context Coding
I personally prefer to call AI-assisted programming methods "Context Coding" - context-based programming or context-driven programming.
The reason is that I believe AI programming progress, besides the most important improvement in LLM programming capabilities (like models upgrading from GPT to Claude), also has another major improvement: different AI programming tools have stronger Context Engineering capabilities.
The widely discussed strongest AI programming tools have evolved from GitHub Copilot to Cursor to Claude Code. I think these products succeeded because their Context Engineering became more scientific.
When the base model stays the same, all improvements in AI-assisted programming are based on the basic principle of passing more suitable context to LLMs, whether through Chat, RAG, Rules, MCP, or other cooler future technologies.
So from the perspective of providing suitable context to LLMs, let's analyze the characteristics of these products to learn how to better use AI for programming assistance.
GitHub Copilot
I believe most people's first encounter with AI-assisted programming tools started with GitHub Copilot. Besides integrating AI chat functionality, what impressed me most was the code completion feature.
Before this, VSCode was always criticized for having inferior code completion compared to IntelliJ IDEA. IDEA achieved code completion through complete code indexing, AST (Abstract Syntax Tree), and smart ranking algorithms. For over a decade, it has been beloved by programmers and was always my favorite IDE.
Regardless of the project language, I used to mindlessly choose IDEA for programming until VSCode Copilot appeared. I started switching between VSCode and IDEA, until later completely abandoning IDEA.
GitHub Copilot's initial success lay in being the first integrator to share code context with LLMs, mainly shown in two capabilities:
First, it could provide currently open IDE window code to LLMs and offer suggestions and questions about current window code.
This was a huge surprise at the time (2023), because most people were copying code to ChatGPT and then copying code from ChatGPT back to IDEs.
Second, it could perform completion operations based on current code file context. Copilot provided LLMs with code context around the cursor position, and LLMs gave suggestions accordingly.
After this feature appeared, my programming habits underwent the first major change: I liked to write method comments first, let Copilot generate corresponding methods based on comments, then modify method details. This pattern greatly accelerated coding speed.
But Copilot's disadvantages were also obvious at the time. First, model capabilities weren't enough. GPT 3.5, while amazing, still had too many hallucinations in programming, and could accept very limited context. So at the time, the probability of fully accepting LLM suggestions and code completions was very limited. Additionally, Copilot + GPT 3.5 didn't have direct code editing capabilities, requiring manual copying of code from LLM suggestions.
Another issue was that Copilot could only provide currently open window code file context to LLMs, so LLMs couldn't give suggestions based on other files or entire project context.
This meant that when you implemented a method in one code file and switched to another file, LLMs didn't have context from that method file, unable to provide completion based on that method call. Not to mention programming tasks spanning multiple files for joint retrieval and modification were unimaginable at the time.
So in this situation, Cursor, which provided better context, stood out.
Cursor
After Copilot appeared, many IDE plugin-form AI assistant tools emerged, differing only in prompts and LLMs. Until Cursor appeared as a complete AI IDE, competition among AI plugin programming assistants ended.
Let's first discuss technical improvements unrelated to context engineering. First, Cursor designed a dedicated model for Tab auto-completion, which impressed me most with its very fast speed and high precision. The probability of accepting code completion was quite high. At the time, there was a joke that programmers evolved from Copy engineers to Tab engineers.
Second was the appearance of Claude 3.5 Sonnet model, which had stronger programming capabilities than GPT models, plus increased context length and direct file editing abilities.
It can be said that the combination of Cursor Tab model and Claude 3.5 Sonnet model evolved AI-assisted programming from "code completion tools" to "programming agents."
Besides this, Cursor's context engineering is also worth learning from.
Cursor's first key breakthrough in context engineering was using RAG (Retrieval Augmented Generation) to index entire project codebases and provide entire project context to LLMs through semantic (vector) search.
If you've noticed, when using Cursor to open a new project, you'll see in Cursor Settings' Indexing section that Cursor starts indexing your entire project, and you can see how many files are currently indexed.
The principle behind this: Cursor splits the entire codebase into multiple small content blocks when you open a new project locally, then uploads them to Cursor cloud servers, using embedding models to embed code and store it in cloud vector databases.
Then when you ask questions in Chat/Agent, Cursor embeds prompts during inference, has Turbopuffer perform nearest neighbor search, sends obfuscated file paths and line ranges back to Cursor client, and reads these file code blocks locally on the client.
Turbopuffer is serverless vector and full-text search built from scratch on object storage. If you're not familiar with vector search, you can simply understand it as semantic search that can find words with similar meanings.
If you want to learn more about embedding and vector databases, you can check my 2023 blogs GPT Application Development and Thinking and Vector Database.
Based on this capability, Cursor can retrieve code context related to your current conversation and provide it to LLMs together. With multiple file contexts, LLMs can:
- Implement cross-file method calls
- Fix bugs involving multiple files
- Refactor entire modules
- Add new features requiring code changes across multiple files
On this foundation, Cursor also supports directly @-mentioning certain files/folders to provide context to LLMs, and later added Git history indexing capabilities.
From a context engineering perspective, Cursor's success over Copilot lies in providing more comprehensive code context to LLMs and giving users more autonomous control over context.
Additionally, Cursor later added document indexing functionality to help provide latest technical documentation context to LLMs. It also added Rules-related functionality to provide general programming rules to LLMs, ensuring LLM-generated code stays consistent with your project architecture, coding style, and tech stack.
All these functions without exception are designed to provide richer, more suitable context to LLMs, so I prefer to call it Context Coding.
Claude Code
When Cursor maintained its leading position through various context engineering optimizations, Claude Code entered the competition in a completely unexpected way. Before Claude Code appeared, I never imagined terminal command-line CLI could be used for LLM-assisted coding.
Although I hadn't experienced terminal command-line AI products before, when the product was first released, I was initially attracted by the Unix style and wanted to try it. But after actual use, it was very easy to get started, with programming effects comparable to Cursor, and in some cases even better than Cursor.
In actual Next.js programming tests, for small to medium programming tasks, Claude Code's effects were similar to Cursor. After all, I usually use Claude 4 sonnet or Opus models for both tools. Cursor still has more convenient programming experience since it includes command + K or Tab completion.
But for large programming tasks, like needing to retrieve and modify more than 10 files at once, Claude Code's programming effects far exceeded Cursor. I think the root reason is that Claude Code provides LLMs with an "all-you-can-eat" context strategy.
Cursor, being downstream from base model providers (like Claude), needs to balance user payments and actual token usage to succeed commercially. So there have been many adjustments that upset programmers: adjusting model speed, usage limits, automatically switching to lower-capability models.
I've long wanted to complain about this. Arbitrarily adjusting usage limits is one thing, but unconsciously switching models to "Auto" low-end models, plus switching IPs to US residential areas - sometimes there are huge differences in model capabilities and speed compared to CN/HK.
In short, under Cursor's commercial balancing and lack of external competition, the actual experience has diminished considerably.
Unlike Cursor, Claude Code, being a product from base language model provider Anthropic, isn't as cautious about consuming tokens.
Claude Code starts by analyzing codebase project structure and basic tech stack information through terminal commands. This differs from Cursor's focus on specific tasks and few code files. Claude Code takes a more global perspective, first analyzing overall project conditions before development. While this definitely consumes more tokens, with this overall project information, Claude Code writes code that better matches the project's original development patterns and coding standards.
Plus Claude Code chose a completely different code context retrieval solution from Cursor: Unix tools-based retrieval. For example, using grep, find, git, cat and other terminal commands instead of RAG solutions.
This approach is generally more in line with programmers' coding habits. For example, when programmers do programming tasks and are unfamiliar with code, they usually start from key method names or object names, gradually doing fuzzy or regex searches layer by layer until finding all business-related code, then start programming.
Claude Code chose this context engineering mode: after you ask questions, it continuously searches based on keywords from your questions until finding all necessary context code in the project, then starts programming. Or it goes through rounds of conversation, programming, and retrieval repeatedly until LLMs think they've found all context.
After Claude Code chose this different approach from Cursor RAG, significant community controversy emerged.
The RAG camp believes grep solutions have low recall rates, retrieve lots of irrelevant content, are not only token-expensive but also inefficient, as LLMs need constant conversation and context retrieval.
The grep camp believes complex programming tasks need precise context, and RAG solutions don't perform well in code retrieval precision. After all, code semantic similarity doesn't equal code-related context, much less business context.
Also, solutions like Cursor's file hash-based Merkle tree index update synchronization can retrieve outdated code during heavy refactoring or when index servers are overloaded, providing stale context.
Both camps make valid points. Claude Code is indeed slower and more token-consuming than RAG solutions, while Cursor doesn't perform as well as Claude Code for complex tasks. I think this is factual from experience.
But overall, I think in an era where large language model capabilities haven't overflowed, we can temporarily not consider speed and token consumption. After all, whether we can ultimately solve engineering problems is currently the most important thing and the primary goal of all AI programming tools. From this perspective, Claude Code is a better choice.
Of course, I don't completely agree with grep solutions. I think in the near future, complete AI IDEs will definitely provide both RAG + Grep capabilities, selectively using them in different situations. Cursor will definitely work on grep solutions rather than relying entirely on RAG.
But for tools like Claude Code and Gemini CLI, I don't think it's necessary to reference Cursor and integrate RAG solutions. Because what some people might not realize is that Claude Code's focus extends beyond programming assistance to direct scriptable workflow collaboration with all development environments. Through bash environment integration with codebases, MCP markets, and DevOps workflows for CI/CD automation.
These environments perfectly adapt to current grep and other retrieval solutions, completely unnecessary to wear RAG's binding cloth. Products like Claude Code have huge imagination space in the above fields and represent blue ocean AI product markets.
How to Better Context Coding
So after learning about context engineering from so many AI products, can we better do Context Coding? I think there's still significant borrowing significance.
Since the key to AI-assisted coding is passing more suitable context to LLMs, sometimes borrowing from our daily development thinking can better help us understand: how to pass better context to LLMs.
Suppose you need to join a new project team. You only have basic knowledge of required technologies and frameworks (LLMs also only have basic technical and framework knowledge).
Then normally after cloning the codebase, the first thing is usually to understand what tech stacks the project uses, then browse the codebase directory structure and try to understand the general project directory structure and layers, trying to understand what different types of named files do. These processes are very helpful for understanding new projects daily.
So the context we provide to LLMs should also include the codebase's general tech stack (what technologies and tools are used), directory structure (project structure and layers), and what corresponding files do (file naming and meanings).
Because LLMs by default have no previous memory for each new session, lacking the above context, we should also save this information in instruction files or rule files, such as GitHub Copilot's .github/copilot-instructions.md file, Cursor's corresponding .rulers folder, and Claude Code's CLAUDE.md file.
Currently, each AI Agent uses different rule file naming with no unification. So if your team uses multiple AI Agents simultaneously, or like me uses Cursor / Claude Code and other tools simultaneously, consider using the Ruler open source project to unify instruction file management.
With the above information, LLMs can get overall project basic context information for every new conversation before programming, consistent with our habit of looking at this information first before developing requirements.
From this perspective, we can think of more project basic context. For example, during regular development, besides understanding the above context, we also look at common commands for new projects, such as install packages, lint, test, build commands. Including finding utility classes, checking what common methods exist, where core business modules, core methods, and core files of new projects are, and what they do. We need this information for better programming development.
So since the above information is very helpful for developing unfamiliar projects, theoretically it's also very helpful for LLMs (which can be simply understood as interns with only basic technical capabilities).
Note that this type of context isn't the more the better, especially easily outdated context information like file directories and easily refactored files and utility classes. Once this information changes but isn't synchronized to instruction rule files, it brings more harm than not providing this context. How to maintain and update such files is a difficult problem, especially for large team projects.
Besides the above basic information, you can also require LLMs to think and develop like experienced programmers. For example, for simple tasks, develop directly. For difficult requirements, first break requirements into multiple subtasks, record or write them in a document, update status to this document after each subtask completion, make small commits for each subtask, and finally delete this document file.
This process can significantly reduce LLM hallucination problems in complex tasks. I observed that Claude Code's coding development process basically uses this pattern, though implementation may differ.
Of course, we can think of more mature development thinking and programming standards like this:
- Incremental changes, small commits
- Learn from existing code, find 2-3 similar implementations, use the same libraries/tools as much as possible
- Code readability is more important than showing off skills
- One function solves one problem; if it needs explanation, it's too complex
- Don't introduce new tools without good reasons
Based on your project requirements and team programming standards, selectively add some thinking and standards to your team project instruction rule files. This is also very useful context for LLMs.
Of course, even if you add all current programming standards and clean code principles to rule files, current LLMs are unlikely to always write code with sufficient abstraction levels and robustness. From my personal experience, having LLMs write good abstractions is still too difficult - maybe the training code doesn't have much well-abstracted code.
Besides project basic information and programming standards, commonly used development tools and debugging techniques are also good context sources for LLMs.
For example, in daily development, when we need to call third-party libraries or latest methods/APIs, the most common thing is to access their official documentation and query latest method names/API paths. It's the same for LLMs. Training data becomes outdated, so it's best to pass latest documentation to LLMs. We can solve this through context7 and other MCP.
Debugging problems is the same. You can have LLMs add logs everywhere in problematic code, mimicking IDE debug mode. This gives LLMs enough debugging information input, like we see input/output parameters for every method in debug mode. You can also get enough good context for LLMs through MCP methods like browser console logs and web search answers.
At this point, I believe everyone can understand that the examples I gave aren't meant to show that the above instructions and rule files are silver bullets that can solve all AI-assisted programming rules and instructions.
Rather, I want to show that since the core of AI-assisted programming is passing suitable context, when LLM effects are poor, we might as well start from our common and familiar development thinking and programming habits to think about how to pass better context to LLMs. Whether this method is Rules or MCP, everything revolves around the goal of context engineering.
Industry giants like Claude Code recently built in /context commands, allowing very intuitive viewing of used context, different tool type proportions, and remaining context.
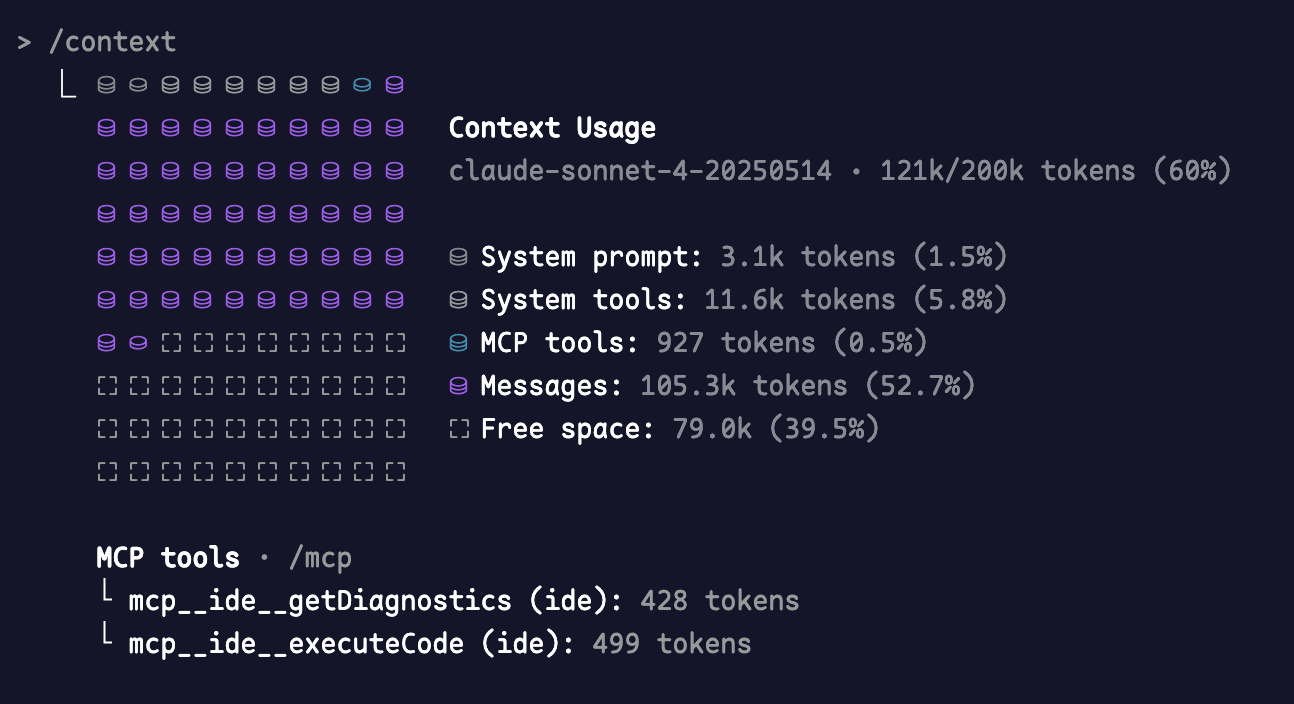
This actually shows Claude team's deep understanding of Context Engineering, thinking from a development perspective about how to manage context while programming.
Helping you know remaining tokens when using LLMs, whether compression processes will be triggered soon, whether context needs early compression, which prompts have large token proportions - helping you understand and clarify token usage, such as whether invalid MCP and tools have excessive proportions.
This should be the first AI tool I've seen that exposes context usage to users, and an AI tool that continuously progresses in context engineering.
The relationship between LLM improvement and context engineering is like the relationship between hardware memory improvement and software memory control management - they don't conflict. When LLM models and context capacity aren't easy to improve, whoever provides better context and does better context engineering is more likely to stand out. This applies not just to AI programming but to all AI products.
Personal Views
Besides the Context Coding techniques and experiences mentioned above, I'll share some personal views.
None of the AI programming tools mentioned above can solve all programming problems. It's not that Claude Code works better, so Cursor has no reason to exist.
Actually, in serious engineering practice, Cursor's Tab code completion is something I use quite often. One reason is the LLM capability limitations I mentioned earlier - it's not too much abstraction, but wrong understanding of my intentions, doing things I don't want.
For example, when creating NextDevKit templates, because template code needs to be more robust and clean, with reasonable module abstraction and layering, relying on LLMs for implementation completely can't improve efficiency.
In such cases, Tab can improve efficiency considerably. For example, write good layering and abstraction yourself, then write comments and method names, use crazy Tab code completion to efficiently generate code. This method is sometimes more efficient than adjusting conversations back and forth and having LLMs output full code directly.
Of course, Tab is sometimes annoying too. Extremely speaking, when I write this blog, there's no way to output content I want to express, so I can only use shortcuts to turn it off.
Claude Code is very helpful for understanding unfamiliar new projects. For example, when I familiarize myself with new projects and codebases, I'm used to having Claude Code help me output overall project information and situations. Help me analyze what places need modification for tasks to be done, complete tasks in unfamiliar tech stacks. Under reasonable programming standard guidance, it's indeed stronger than doing it myself.
In short, good engineers can always choose suitable tools to solve problems, rather than being tool believers who need tools to prove their value.
Besides this, LLMs have also changed some of my original programming habits. For example, I used to like researching IDE tricks and shortcuts to help reduce time spent on repetitive coding.
Now I have to thank LLMs for liberating these annoying, boring tasks. Also, like before I was used to using IDE debug mode to debug problems, now I generally have LLMs generate lots of logs directly, then rollback and delete after debugging. Also similar to one-time code and scripts - before I needed to struggle with whether writing scripts or doing manually was faster, now I uniformly have LLMs generate them, no more internal conflict and waiting.
Also for some engineering requirements, no need to worry about code quality and reuse problems - complete tasks then delete these low-quality but effective code. Generate from scratch next time for similar requirements, which is more effective and manageable than building reusable engineering code.
And sometimes no need to care about code quality, like generating demos for customer presentations or building new product features. Get good feedback and users before considering refactoring and quality; delete directly if not good.
These are all changes that happened after having LLM assistance. I'm not sure if these changes are good, but in this era, we indeed need to rethink code and products. Changing can always bring more thinking.
Vibe Coding
After discussing so much Context Coding experience and views, we can finally talk about Vibe Coding.
After reading the above content, you should be very clear that for an experienced programmer to write readable, maintainable code that can support future requirement changes with LLM assistance is still not easy. So for someone without programming experience to completely use Vibe Coding to get a product online and support future requirement changes is still very difficult at this stage.
In the short term, Vibe Coding will introduce defects and security vulnerabilities. Long term, Vibe Coding will make code hard to maintain, accumulate technical debt, and greatly reduce overall system understandability and stability.
The most vivid explanation I've seen is that letting a non-programmer write a large project they intend to maintain through Vibe Coding is like giving a child a credit card without first explaining the concept of debt.
When building new features, it's like waving this little plastic card, buying whatever you want, writing whatever new features very quickly. Only when you need to maintain it does it become debt.
If you try to use Vibe Coding to fix another Vibe Coding-caused problem, it's like using another credit card to pay credit card debt.
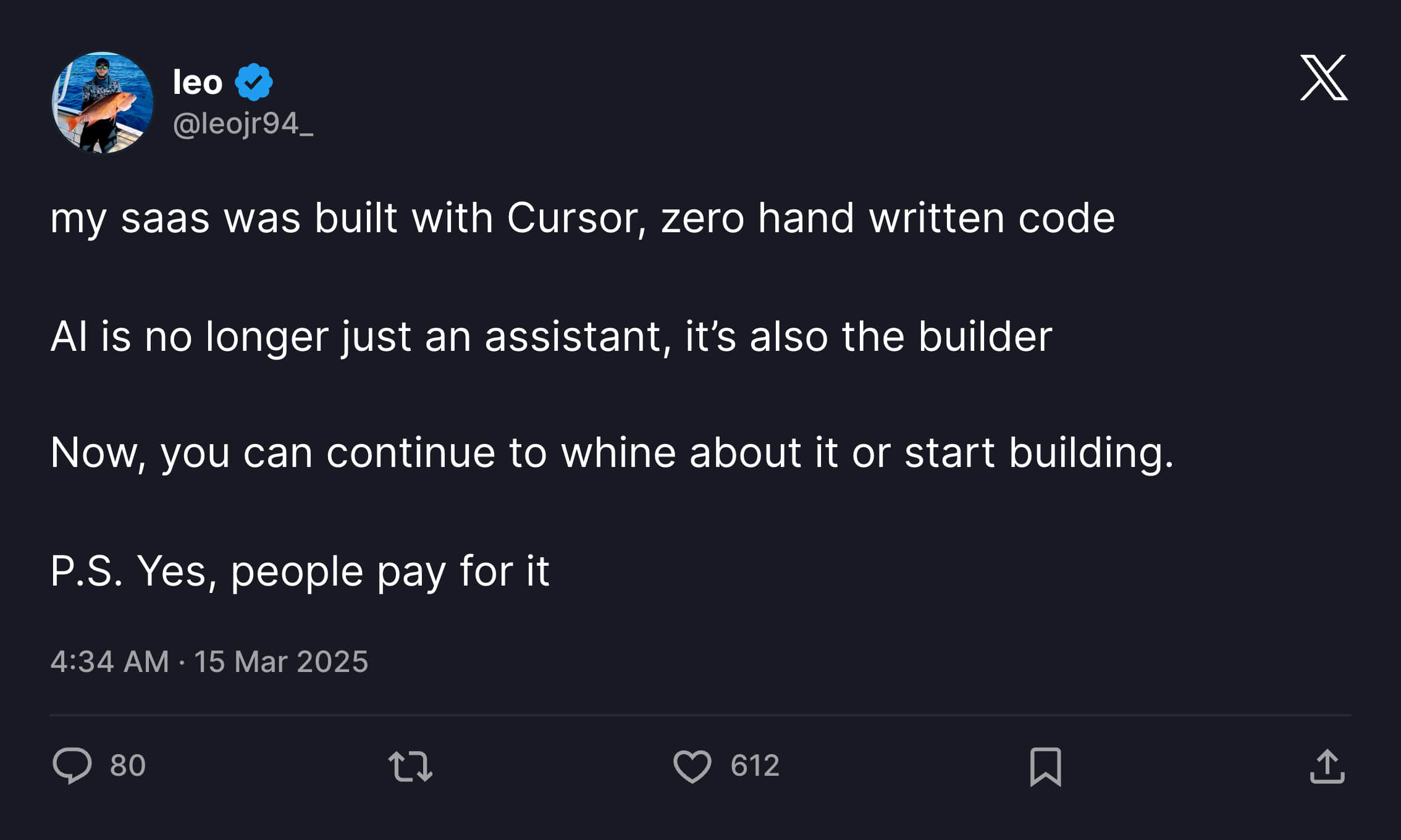
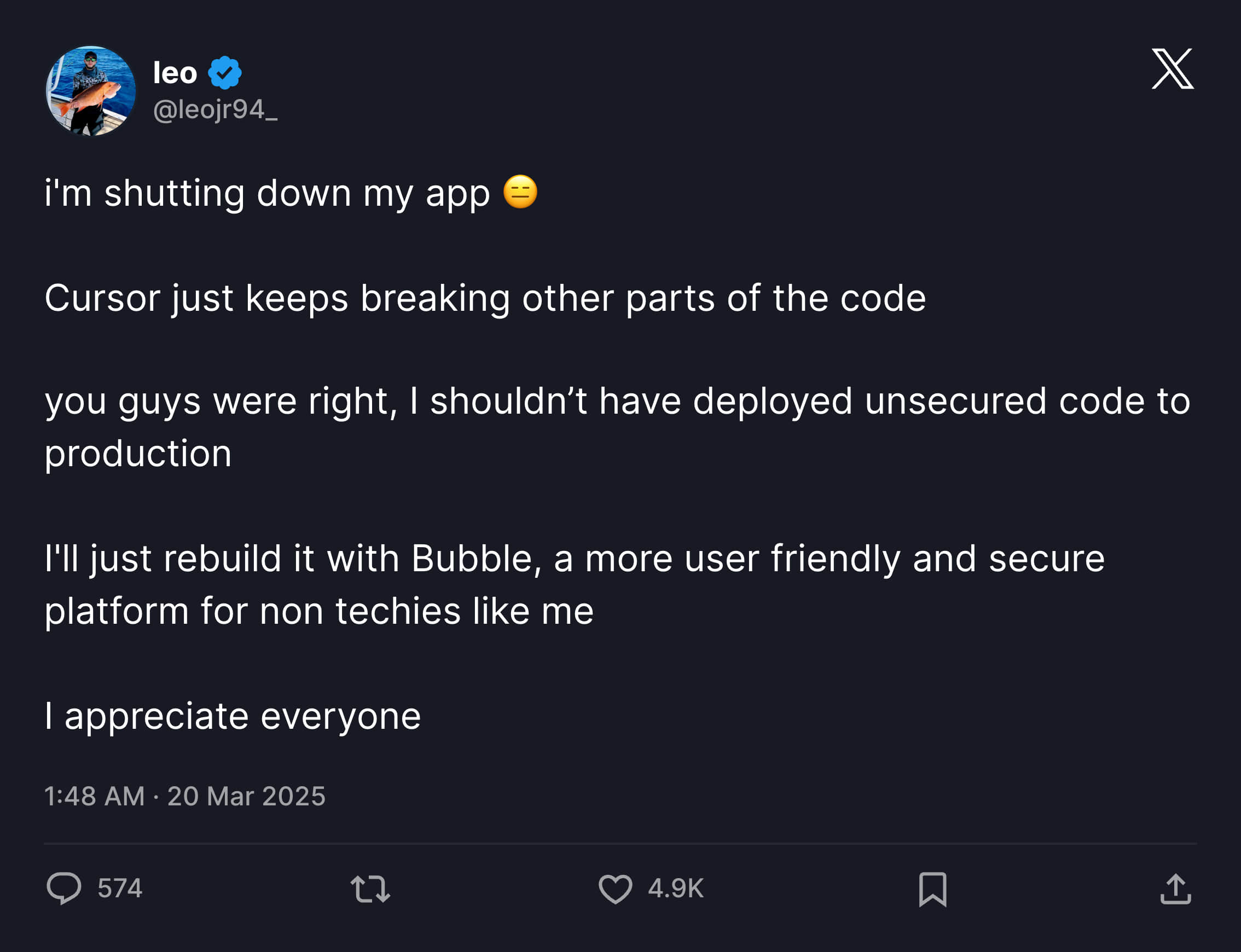
The best annotation for this should be Leo's story on X. On March 15 this year, he posted about using Cursor through Vibe Coding to make a product. Without manually writing any code, the product gained paying users.
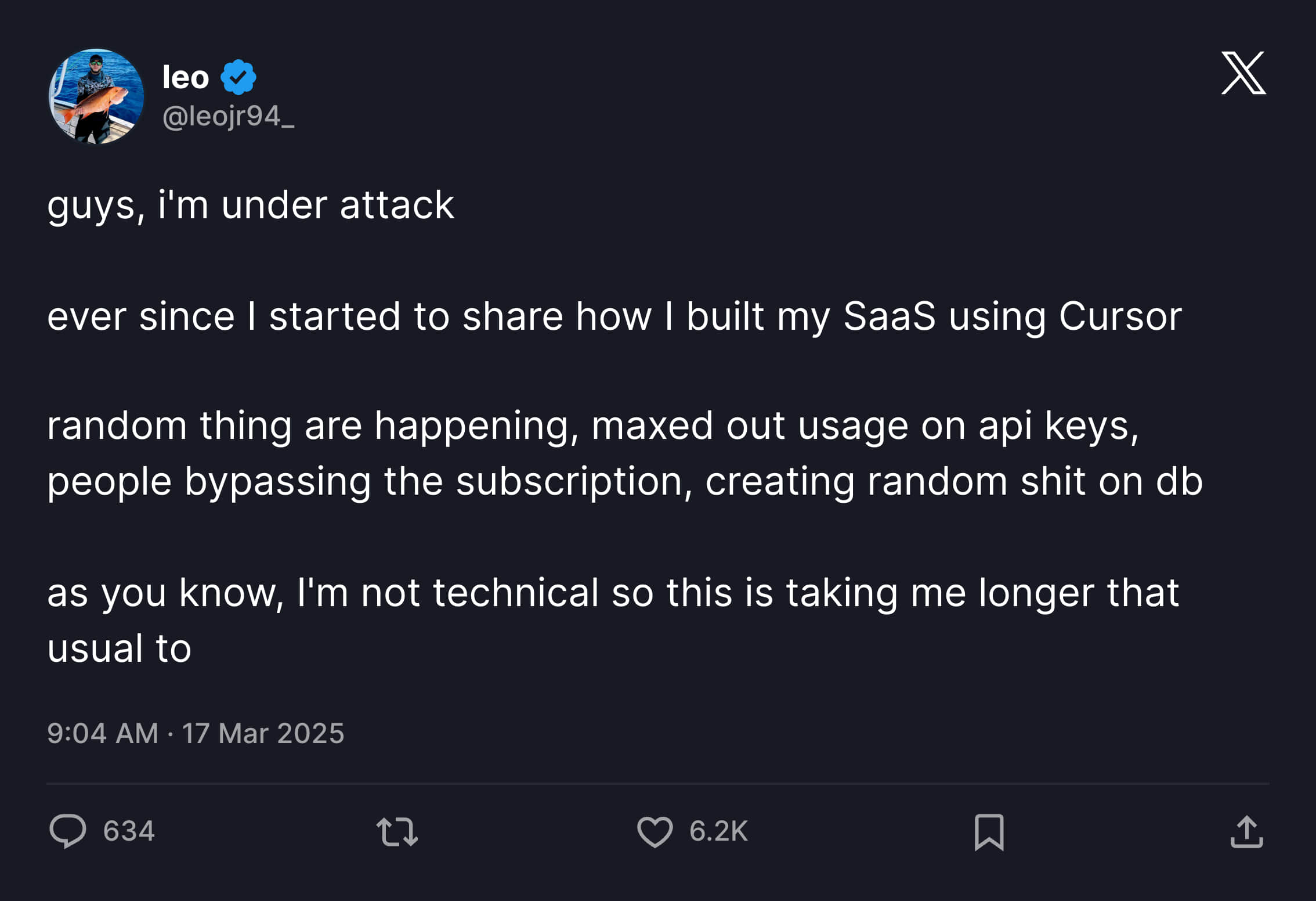
But just two days later, things changed. After the previous post went viral, people attacked his product. API key usage reached maximum values, people bypassed subscriptions, randomly creating things in the database.
Because Leo was unfamiliar with technology, solving each problem took much longer than building features through Vibe Coding.
Finally, on the 20th, Leo had to shut down his product and admitted he shouldn't deploy insecure code to production environments.
Seeing this story's ending, most programmers should be able to breathe a sigh of relief temporarily. After all, this means no short-term unemployment risk, personal value still exists. But long term? How to think about career paths?
I've always held a pessimistic attitude. In 2023, I mentioned that in modern social division of labor, a few excellent programmers improve code quality and performance, analyze and solve technical problems, create new solutions, design system structures and algorithms. But most programmers work as translators, converting people's natural language requirements and business logic into code that computers can understand and execute.
This is like complaining that bosses don't understand programming and treat code quantity as work quantity, while bosses complain you don't understand business. From a technical perspective, programming essence is theory construction, creative output.
From a business perspective, capital subdivides programmers into frontend, backend, algorithms, and even more subdivided fields. The advantage is productivity improvement - subdivision focus enables better technical innovation and talent development. The disadvantage is labor alienation - programmers are no longer creative outputters but single-field producers, screws in production processes, becoming translators who lose independence and are easily replaceable.
This means Vibe Coding fundamentally revolutionizes the programming industry. As LLM capabilities grow, people discover LLMs can also serve as translators. Vibe Coding will continuously erode and squeeze programmers' survival space.
From this stage, the number of average programmers will start decreasing until disappearing. This process is less about AI stealing jobs than excellent programmers stealing jobs, and income differences between them will continue growing during this phase.
The great tide of the times rolls on majestically. I don't want to think too pessimistically about the future or speak too cruelly, but under industrial machinery's roar, no one truly cares about traditional handcraft makers' voices. Before computers appeared, you could hardly imagine how large groups ticket sellers and telephone operators were.
Of course, I'm not saying average programming level programmers have no way out. Actually, with AI assistance, an average programming level programmer with good business instincts plus some marketing ability creates much more business value than being a screw in social division of labor.
Past work that might have required many people collaborating can greatly reduce work time and personnel scale using AI leverage. Future independent development and small team collaboration will definitely become more mainstream.
Like also in March this year, famous independent developer Peter Levels launched a completely Vibe Coding product: real-time flight simulator MMO game.
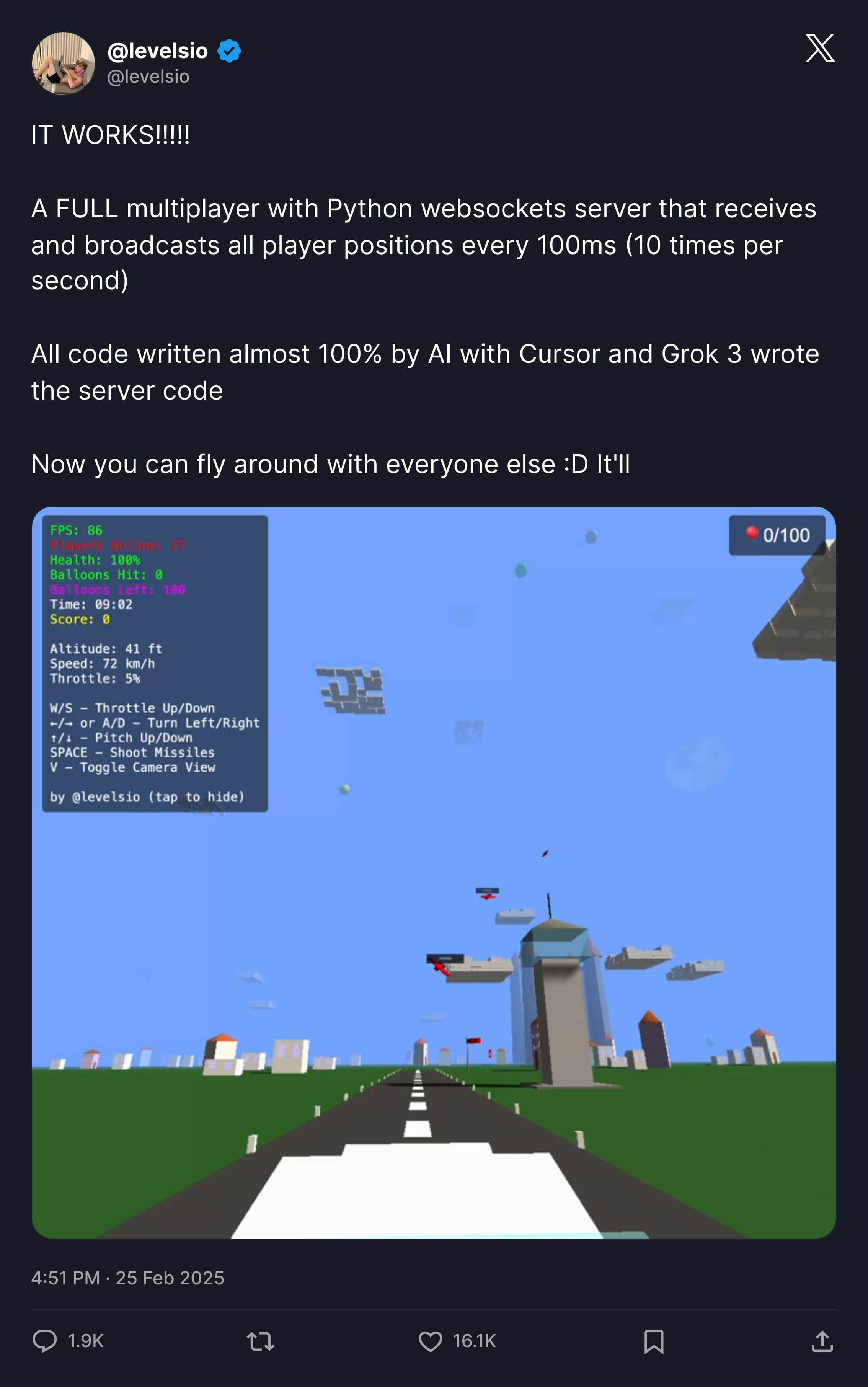
The author also claimed almost all code was 100% implemented by AI + Cursor + Grok 3, earning large income by selling in-game advertising spots, going from 0 to $1M ARR in just 17 days.
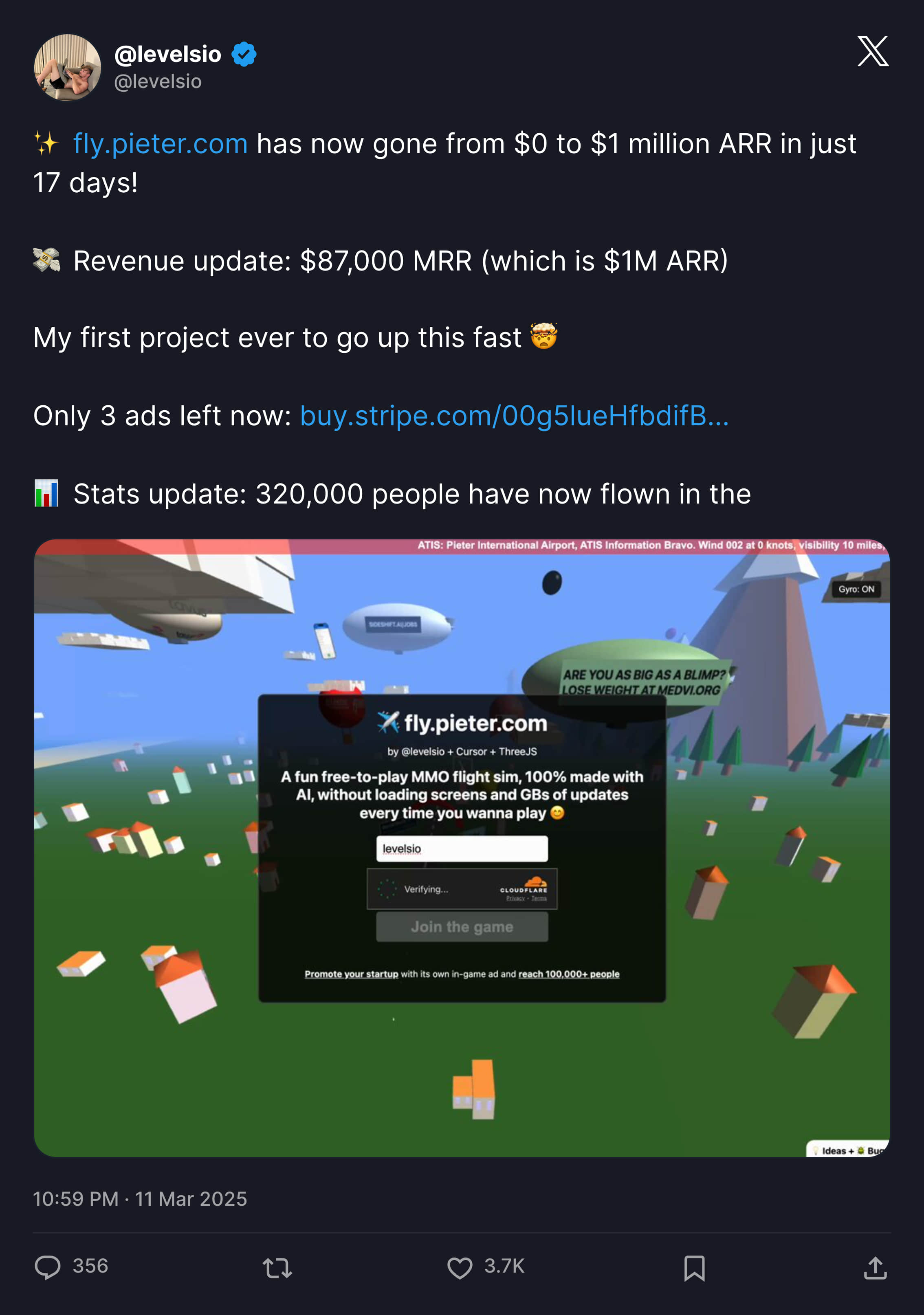
Of course, Levels was already an experienced independent developer with rich programming experience before doing this project, completely capable of taking over the project anytime. And I think this product's success might not be so successful with different timing and founders.
This example just wants to show that jobs and positions may disappear, but needs and opportunities will always exist.
In this era, the only thing that can solve this problem and anxiety is continuous learning and constant practice. I personally believe the programmer community has the strongest learning spirit. Regardless of industry changes, people with continuous learning ability can never be replaced.
I hope we can all find paths we prefer more in the new era. This article was written hastily and contains many personal opinions. If you have different views, please feel free to comment below.
References
- https://x.com/leojr94_/status/1901560276488511759
- https://x.com/leojr94_/status/1902537756674318347
- https://x.com/leojr94_/status/1900767509621674109
- https://x.com/karpathy/status/1959703967694545296
- https://cursor.com/security#codebase-indexing
- https://blog.val.town/vibe-code
- https://pages.cs.wisc.edu/~remzi/Naur.pdf
- https://x.com/levelsio/status/1899596115210891751
- https://x.com/levelsio/status/1894429987006288259